
PDFMinerを使用すると、Pythonを使用してpdfからテキストを抽出することができます。
本記事では、PDFMinerを使用した、pdfからテキストを抽出する方法について、詳しくご説明します。
- PDFMinerのインストール方法を知りたい人
- pdfからテキストを抽出する方法を知りたい人
PDFMinerとは
PDFMinerは、Pythonを使用してPDFを操作するための外部ライブラリの1つです。
PDF操作用ライブラリはPDFMinerの他にも、PyPDF2やReportLabなどいくつか存在します。
それぞれのライブラリの用途は、以下の通りです。
| ライブラリ | 用途 |
|---|---|
| PDFMiner | ・テキストの抽出 |
| PyPDF2 | ・画像の抽出 ・PDFファイルの結合や分割 |
| ReportLab | ・PDFの新規作成 |
本記事では、PDFMinerによるテキストの抽出をご紹介します。
PDFMinerのインストール
PDFMinerシリーズのうち、本記事では「pdfminer.six」をインストールします。
「pdfminer.six」は、以下コマンドを入力することで、インストールすることができます。
コマンドの入力は、コマンドプロンプトあるいはターミナルから行います。
pip install pdfminer.six動作確認として、試しに以下を入力します。
from pdfminer.pdfinterp import PDFResourceManager上記を入力してもエラーが発生しなければ、正常にインストールされています。
PDFからテキストを抽出する
テキスト抽出用のクラス
「pdfminer.six」を使用して、テキストを抽出するためのクラスは以下の通りです。
| ライブラリ | 機能 |
|---|---|
| PDFResourceManager | PDFファイル内のコンテンツを管理 |
| TextConverter | PDFファイル内のテキストを取得 |
| PDFPageInterpreter | PDFページを解析 |
| PDFPage | PDFページを1ページずつ取得 |
| LAParams | PDFファイルのレイアウトを保持 |
PDFファイルの読み込みとテキストの抽出
以下PDFファイルを読み込んで、テキストを抽出してみます。

#input
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.layout import LAParams
from io import StringIO
path = "sample009.pdf"
# ファイルオブジェクトを受け取り、変数「pdf」に代入。
with open(path , "rb") as pdf:
# IOクラス「StringIO」使用(コンソールに出力されたテキストを取得)
output = StringIO()
resource_manager = PDFResourceManager()
# レイアウト変更なし
laparams = LAParams()
text_converter = TextConverter(resource_manager, output, laparams=laparams)
page_interpreter = PDFPageInterpreter(resource_manager, text_converter)
for i_page in PDFPage.get_pages(pdf):
page_interpreter.process_page(i_page)
text = output.getvalue()
output.close()
text_converter.close()
print(text)#output
[Street Address], [City, ST ZIP Code]•[Phone number]•[E-mail address]
[Your Name]
Objective
[Describe your career goal or ideal job.]
Professional Accomplishments
[Field or Area of Accomplishment]
[Job responsibility/achievement]
[Job responsibility/achievement]
[Job responsibility/achievement]
▪
▪
▪
[Field or Area of Accomplishment]
[Job responsibility/achievement]
[Job responsibility/achievement]
[Job responsibility/achievement]
▪
▪
▪
[Field or Area of Accomplishment]
[Job responsibility/achievement]
[Job responsibility/achievement]
[Job responsibility/achievement]
▪
▪
▪
[Field or Area of Accomplishment]
[Job responsibility/achievement]
[Job responsibility/achievement]
[Job responsibility/achievement]
▪
▪
▪
Employment History
[Dates of employment]
[Dates of employment]
[Dates of employment]
[Dates of employment]
Education
[Job title]
[Job title]
[Job title]
[Job title]
[Company Name], [City, ST]
[Company Name], [City, ST]
[Company Name], [City, ST]
[Company Name], [City, ST]
[Date of graduation]
[Degree]
[School Name], [City, ST]
References
References are available on request.PDFのテキストを抽出することができました。
出力結果の改行が不要な場合には、以下を入力することで、改行なしのテキストを出力することができます。
#input
text = text.replace("\n", "")
print(text)#output
[Street Address], [City, ST ZIP Code]•[Phone number]•[E-mail address] [Your Name] Objective [Describe your career goal or ideal job.] Professional Accomplishments [Field or Area of Accomplishment] [Job responsibility/achievement] [Job responsibility/achievement] [Job responsibility/achievement] ▪ ▪ ▪ [Field or Area of Accomplishment] [Job responsibility/achievement] [Job responsibility/achievement] [Job responsibility/achievement] ▪ ▪ ▪ [Field or Area of Accomplishment] [Job responsibility/achievement] [Job responsibility/achievement] [Job responsibility/achievement] ▪ ▪ ▪ [Field or Area of Accomplishment] [Job responsibility/achievement] [Job responsibility/achievement] [Job responsibility/achievement] ▪ ▪ ▪ Employment History [Dates of employment] [Dates of employment] [Dates of employment] [Dates of employment] Education [Job title] [Job title] [Job title] [Job title]
[Company Name], [City, ST] [Company Name], [City, ST] [Company Name], [City, ST] [Company Name], [City, ST] [Date of graduation] [Degree] [School Name], [City, ST] References References are available on request.PDFのテキストを改行なしで出力することができました。
しおり(目次)の取得
「pdfminer.six」を使用すると、PDFの「しおり(目次)」も取得することができます。
以下「しおり(目次)」が含まれたPDFを使用して、「しおり(目次)」を取得してみます。
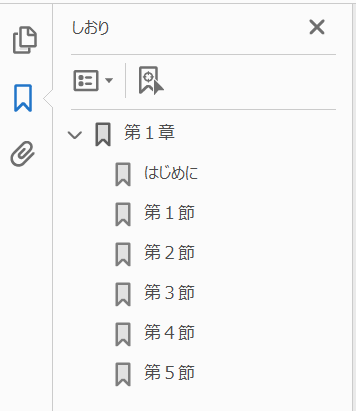
#input
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfdocument import PDFNoOutlines
from pdfminer.pdfparser import PDFParser
path = "sample003.pdf"
with open(path, "rb") as pdf:
# ファイルオブジェクトからParserオブジェクトを取得
parser = PDFParser(pdf)
# ParserオブジェクトからDocumentオブジェクトを作成
document = PDFDocument(parser)
try:
outlines = document.get_outlines()
for outline in outlines:
print(outline)
except PDFNoOutlines:
print("no data")#output
(1, '第1章', None, <PDFObjRef:9>, None)
(2, 'はじめに', None, <PDFObjRef:12>, None)
(2, '第1節', None, <PDFObjRef:14>, None)
(2, '第2節', None, <PDFObjRef:16>, None)
(2, '第3節', None, <PDFObjRef:18>, None)
(2, '第4節', None, <PDFObjRef:20>, None)
(2, '第5節', None, <PDFObjRef:22>, None) PDFのしおり(目次)を抽出・出力することができました。
まとめ
この記事では、PDFMinerを使用した、pdfからテキストを抽出する方法について、ご説明しました。
本記事を参考に、ぜひ試してみて下さい。
参考
Python学習用おすすめ教材
Pythonの基本を学びたい方向け
統計学基礎を学びたい方向け
Pythonの統計解析を学びたい方向け
おすすめプログラミングスクール
Pythonをはじめ、プログラミングを学ぶなら、TechAcademy(テックアカデミー)がおすすめです。
私も入っていますが、好きな時間に気軽にオンラインで学べますので、何より楽しいです。
現役エンジニアからマンツーマンで学べるので、一人では中々続かない人にも、向いていると思います。
無料体験ができますので、まずは試してみてください!
