
スポンサーリンク
データの最頻値は、統計処理の基本であり、Pythonで容易に出力可能です。
本記事では、そんなPython基礎となるデータ最頻値について、詳しくご説明します。
こんな人に読んでほしい
- Python初心者の人
- Pythonによるデータ最頻値の確認方法を学びたい人
データ最頻値
データ最頻値(mode)とは、データのうち、頻度が最大の値のことです。
一意とは限らず、一様分布のデータでは、すべての値が最頻値になります。
そんなデータ最頻値を求める方法について、以下にご紹介します。
statistics.mode()
statisticsモジュールのstatistics.mode()を使用して、データ最頻値を出力できます。
データ集合の例は、以下とします。
#input
import numpy as np
import matplotlib.pyplot as plt
data = [1,7,4,5,9,0,7,4,2,1,7,9,7,1]
fig = plt.figure()
A = fig.add_subplot(111)
A.set_title("histogram",fontsize=18)
A.set_xlabel("data",fontsize = 14)
A.set_ylabel("frequency",fontsize = 14)
A.set_xlim(0,10)
A.hist(data,range=(0,10),color="lime")
plt.show()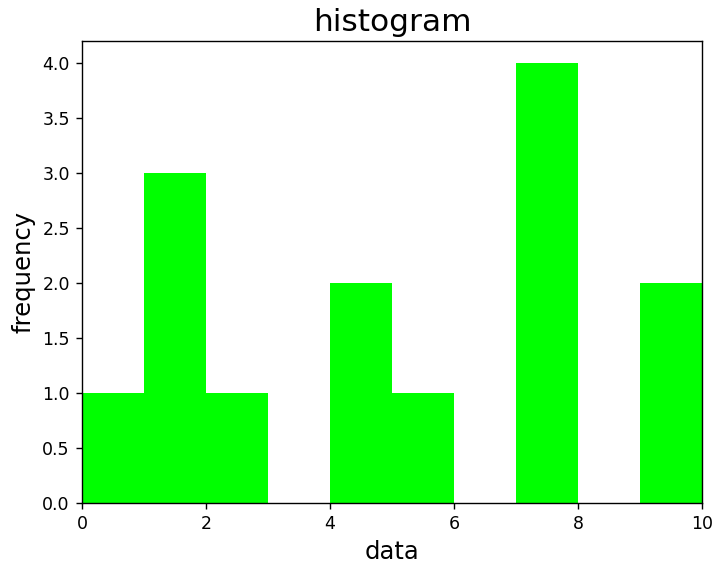
出力されたヒストグラムから、このデータの最頻値は「7」であることが分かります。
このデータ集合の最頻値を確認してみます。
#input
import statistics as st
data = [1,7,4,5,9,0,7,4,2,1,7,9,7,1]
mode = st.mode(data)
print("データ最頻値:{}".format(mode))#output
データ最頻値:7ヒストグラムと同様に、最頻値は7が出力されました。
statistics.mode()関数は数値データだけでなく、文字列データの最頻値(最も多く含まれる文字)も出力できます。
以下に文字列の場合の例をご紹介します。
#input
import statistics as st
string = "Apple Pie"
mode = st.mode(string)
print(string,"の最頻文字:{}".format(mode))#output
Apple Pie の最頻文字:pscipy.stats.mode()
SciPyのscipy.stats.mode()を使用すると、配列の最頻値と頻度を出力することができます。
最頻値が複数ある場合には、その中の最小値が出力されます。
以下に例をご紹介します。
#input
import numpy as np
import scipy.stats as st
data = np.array([[7,8,9,7,5],
[5,2,0,2,4],
[2,1,0,7,9]])
mode1,count1 = st.mode(data,axis=0)
mode2,count2 = st.mode(data,axis=1)
mode3,count3 = st.mode(data,axis=None)
print("データ最頻値(列):{}".format(mode1))
print("データ頻度(列):{}".format(count1))
print("データ最頻値(行):\n{}".format(mode2))
print("データ頻度(行):\n{}".format(count2))
print("全データ最頻値:{}".format(mode3))
print("全データ頻度:{}".format(count3))#output
データ最頻値(列):[[2 1 0 7 4]]
データ頻度(列):[[1 1 2 2 1]]
データ最頻値(行):
[[7]
[2]
[0]]
データ頻度(行):
[[2]
[2]
[1]]
全データ最頻値:[2]
全データ頻度:[3]まとめ
この記事では、Python基礎となるデータ最頻値について、ご説明しました。
本記事を参考に、ぜひ試してみて下さい。
参考
Python学習用おすすめ教材
Pythonの基本を学びたい方向け
リンク
統計学基礎を学びたい方向け
リンク
Pythonの統計解析を学びたい方向け
リンク
おすすめプログラミングスクール
Pythonをはじめ、プログラミングを学ぶなら、TechAcademy(テックアカデミー)がおすすめです。
私も入っていますが、好きな時間に気軽にオンラインで学べますので、何より楽しいです。
現役エンジニアからマンツーマンで学べるので、一人では中々続かない人にも、向いていると思います。
無料体験ができますので、まずは試してみてください!

\まずは無料体験!/
スポンサーリンク