
seabornを使用すると、Pythonを使用してデータを可視化することができます。
本記事では、seabornによるクラスターマップの描画方法について、詳しくご説明します。
- Pythonを使用したデータの可視化方法を知りたい人
- seabornによるクラスターマップの描画方法を知りたい人
seabornとは
seabornは、Pythonを使用してデータを可視化するための外部ライブラリの1つです。
データ可視化用ライブラリは他にも複数あり、その中でも特にMatplotlibが有名です。
seabornはMatplotlibをベースに作られており、Matplotlibの描画機能を利用しています。
seabornの長所は、Matplotlibよりも美しい図を、より少ないコードで簡単に描ける点です。
本記事では、seabornによるクラスターマップの描画方法をご紹介します。
seabornのインストール
「seaborn」は、以下コマンドを入力することで、インストールすることができます。
コマンドの入力は、コマンドプロンプトあるいはターミナルから行います。
pip install seaborn動作確認として、試しに以下を入力します。
import seaborn as sns上記を入力してもエラーが発生しなければ、正常にインストールされています。
クラスターマップの描画方法
seaborn.clustermap()関数を使用することで、クラスターマップを描画することができます。
クラスターマップとは、ヒートマップの一種で、行列データを階層的にクラスター化したグラフになります。
clustermap()関数の引数には、メソッド、メトリック、カラー、データセット等を指定します。
データセットの「iris」を用いて、クラスターマップを描画してみます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
sns.clustermap(iris)
plt.show()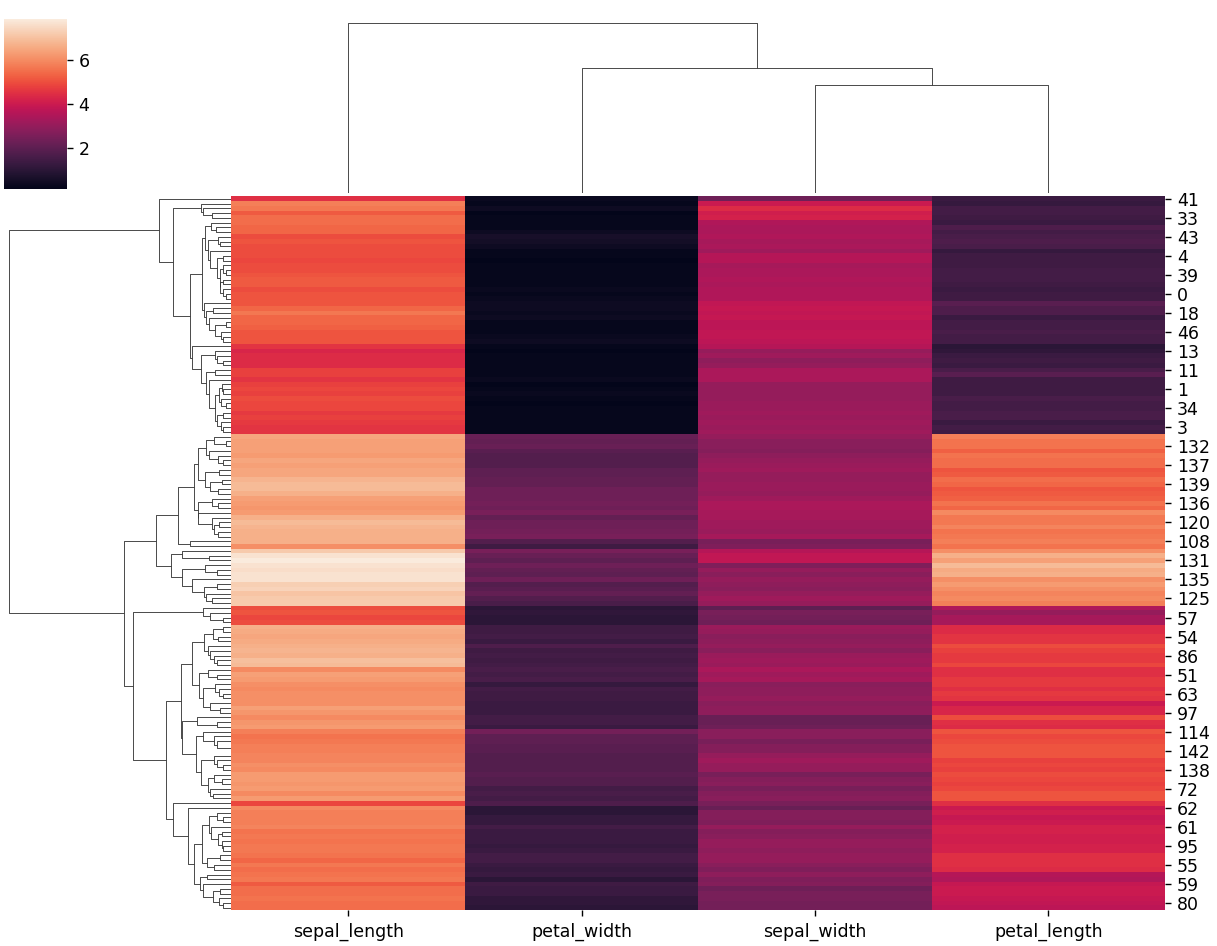
サイズやレイアウトを自由に指定することができます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4))
plt.show()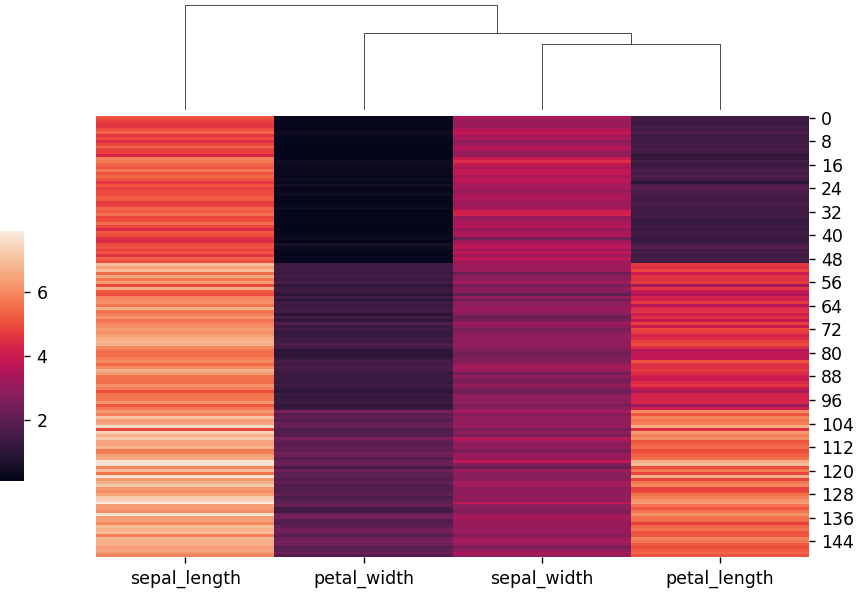
識別用に、色付きのラベルを追加することができます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4), row_colors=row_colors)
plt.show()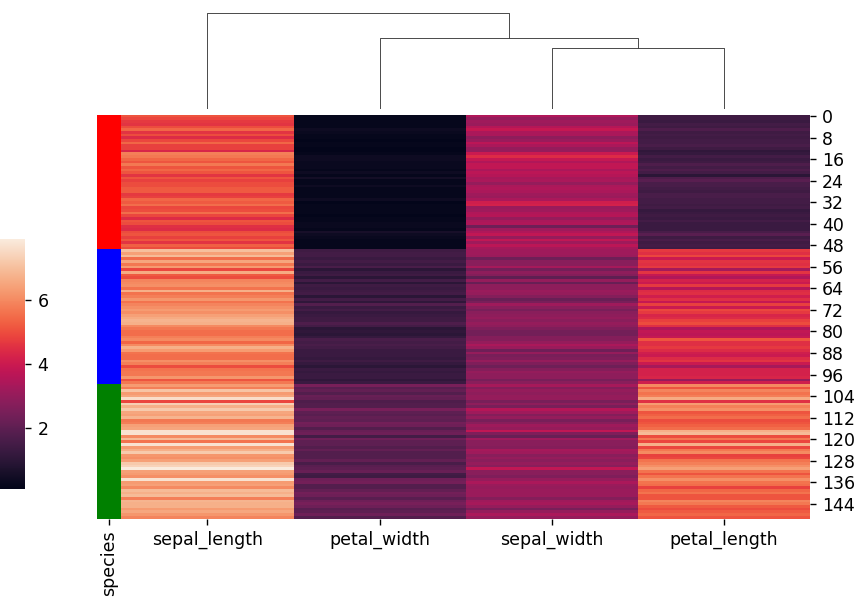
cmapを指定することで、カラーマップを変更することができます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4),
cmap="spring", vmin=0, vmax=10)
plt.show()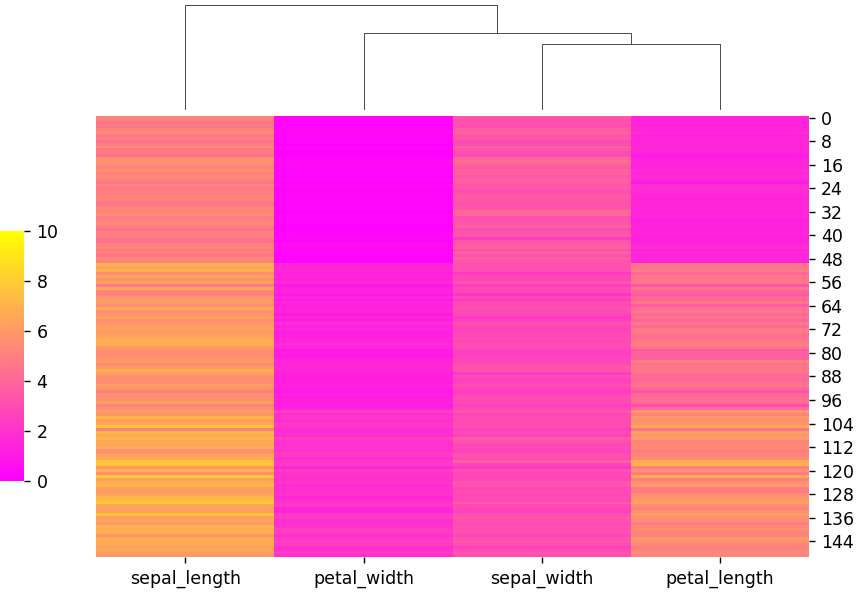
metricとmethodを指定することで、クラスタリングパラメータを変更できます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4),
metric="correlation", method="single")
plt.show()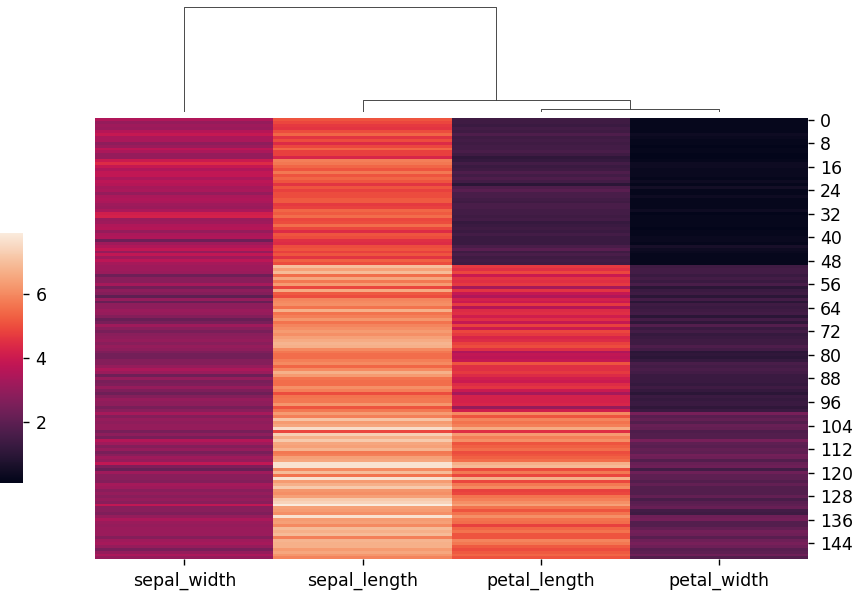
standard_scale=1を指定することで、列内のデータを標準化することができます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4),
standard_scale=1)
plt.show()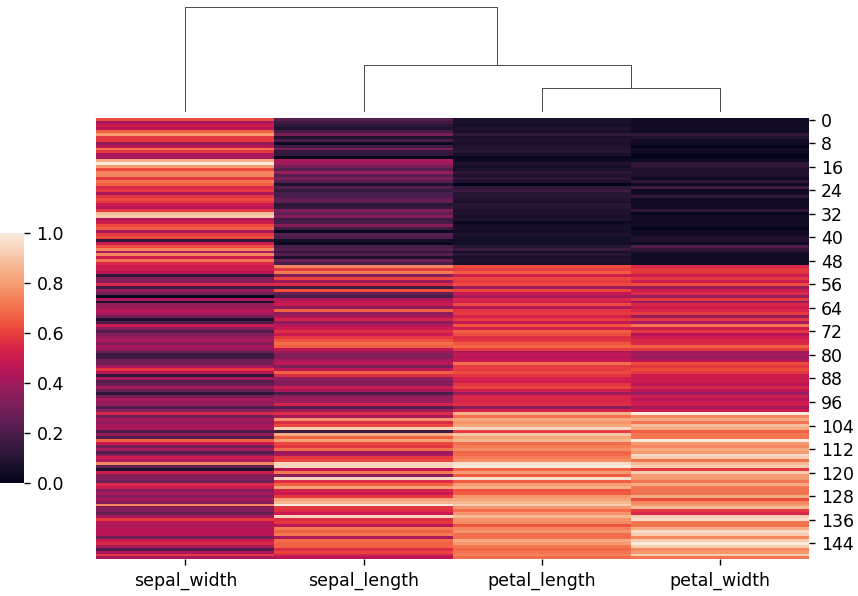
z_score=0を指定することで、行内のデータを正規化することができます。
#input
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# データセットの読み込み
iris = sns.load_dataset("iris")
# clustermapの指定・描画
species = iris.pop("species")
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut)
sns.clustermap(iris, figsize=(7, 5), row_cluster=False,
dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4),
z_score=0, cmap="bwr", center=0)
plt.show()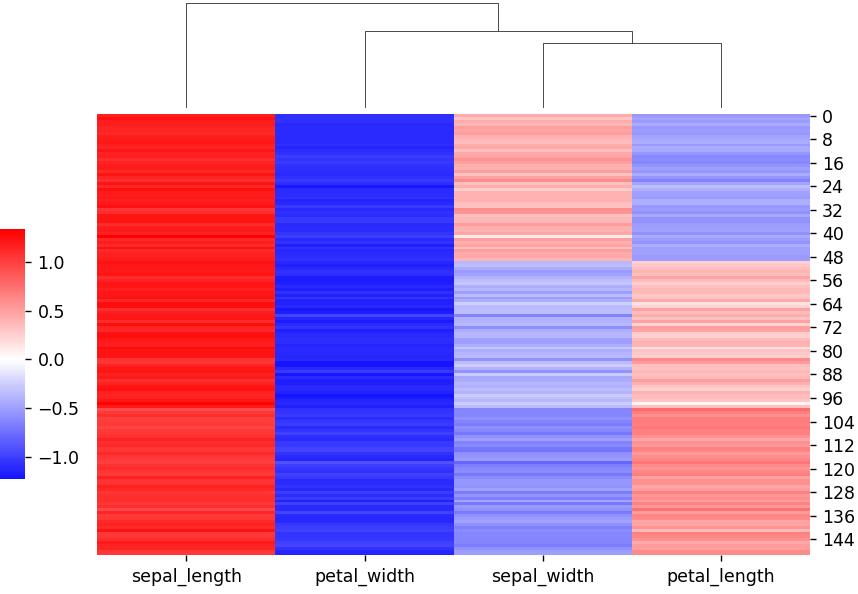
まとめ
この記事では、seabornによるクラスターマップの描画方法について、ご説明しました。
本記事を参考に、ぜひ試してみて下さい。
参考
Python学習用おすすめ教材
Pythonの基本を学びたい方向け
統計学基礎を学びたい方向け
Pythonの統計解析を学びたい方向け
おすすめプログラミングスクール
Pythonをはじめ、プログラミングを学ぶなら、TechAcademy(テックアカデミー)がおすすめです。
私も入っていますが、好きな時間に気軽にオンラインで学べますので、何より楽しいです。
現役エンジニアからマンツーマンで学べるので、一人では中々続かない人にも、向いていると思います。
無料体験ができますので、まずは試してみてください!
