
PyPDF4を使用すると、Pythonを使用してPDFから画像を抽出することができます。
本記事では、PyPDF4を使用した、PDFから画像を抽出する方法について、詳しくご説明します。
- Pythonを使用したPDFの操作方法を知りたい人
- PDFから画像を抽出する方法を知りたい人
PyPDF4とは
PyPDF4は、Pythonを使用してPDFを操作するための外部ライブラリの1つです。
PDF操作用ライブラリは他にも、PDFMinerやReportLabなどいくつか存在します。
それぞれのライブラリの用途は、以下の通りです。
| ライブラリ | 用途 |
|---|---|
| PyPDF4 | ・画像の抽出 ・PDFファイルの結合や分割 ・しおり(目次)の追加 |
| PDFMiner | ・テキストの抽出 |
| ReportLab | ・PDFの新規作成 |
本記事では、PyPDF4によるPDFから画像を抽出する方法をご紹介します。
PyPDF4のインストール
「PyPDF4」は、以下コマンドを入力することで、インストールすることができます。
コマンドの入力は、コマンドプロンプトあるいはターミナルから行います。
pip install PyPDF4動作確認として、試しに以下を入力します。
from PyPDF4 import PdfFileReader上記を入力してもエラーが発生しなければ、正常にインストールされています。
PDFから画像を抽出する
PyPDF4の「PdfFileReader」クラスのPageオブジェクトから画像データを探索・抽出することができます。
画像データの探索は、「/Resorces」キー配下の「/Xobject」キー内にて実行します。
以下PDFを使用して、画像を抽出してみます。

画像(PNGファイル)の抽出
PNGファイルの抽出方法を、以下にご紹介します。
#input
from PyPDF4 import PdfFileReader
from PIL import Image
# 画像抽出用PDFを取得(バイナリモード)
pdf = open("sample014.pdf", 'rb')
reader = PdfFileReader(pdf)
# Page数を取得
pgnum = reader.getNumPages()
# Pageオブジェクトを取得
for i in range(pgnum):
pg = reader.getPage(i)
# Pageオブジェクトの探索
if '/XObject' in pg['/Resources']: # (1)
xobjs = pg['/Resources']['/XObject']
for key, obj in xobjs.items():
item = obj.getObject()
if item['/Subtype'] == '/Image': # (2)
if '/Filter' in item and item['/Filter'] == '/FlateDecode':
# PageオブジェクトからPNGファイルのバイナリデータを取得・出力
size = (item['/Width'], item['/Height'])
data = item.getData()
img = Image.frombytes("RGB", size, data)
img.save(key[1:]+".png")
pdf.close()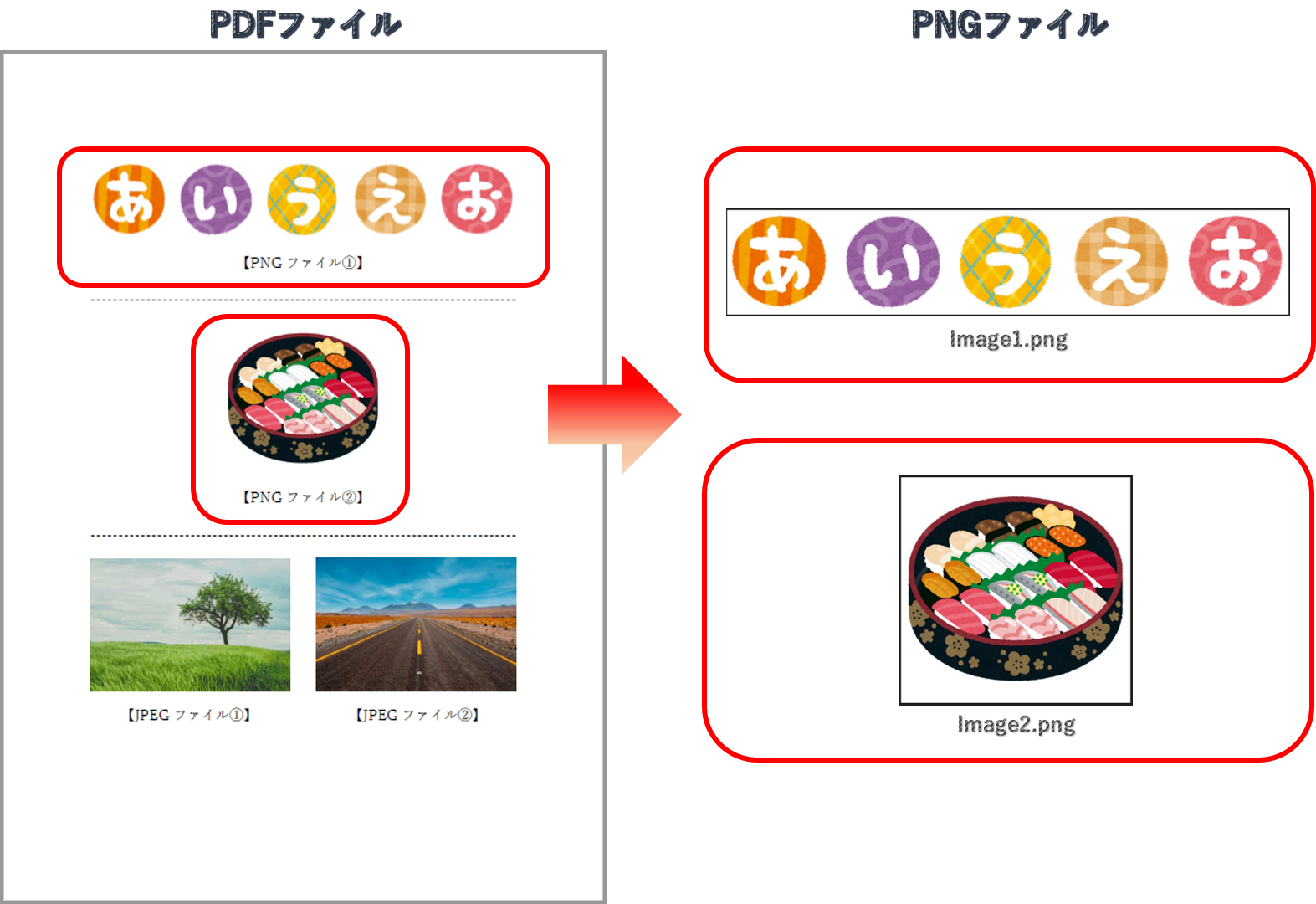
画像(JPEGファイル)の抽出
JPEGファイルの抽出方法を、以下にご紹介します。
#input
from PyPDF4 import PdfFileReader
# 画像抽出用PDFを取得(バイナリモード)
pdf = open("sample014.pdf", 'rb')
reader = PdfFileReader(pdf)
# Page数を取得
pgnum = reader.getNumPages()
# Pageオブジェクトを取得
for i in range(pgnum):
pg = reader.getPage(i)
# Pageオブジェクトの探索
if '/XObject' in pg['/Resources']: # (1)
xobjs = pg['/Resources']['/XObject']
for key, obj in xobjs.items():
item = obj.getObject()
if item['/Subtype'] == '/Image': # (2)
if '/Filter' in item and item['/Filter'] == '/DCTDecode':
# PageオブジェクトからJPEGファイルのバイナリデータを取得・出力
data = item.getData()
img = open(key[1:]+".jpg", 'wb')
img.write(data)
img.close()
pdf.close()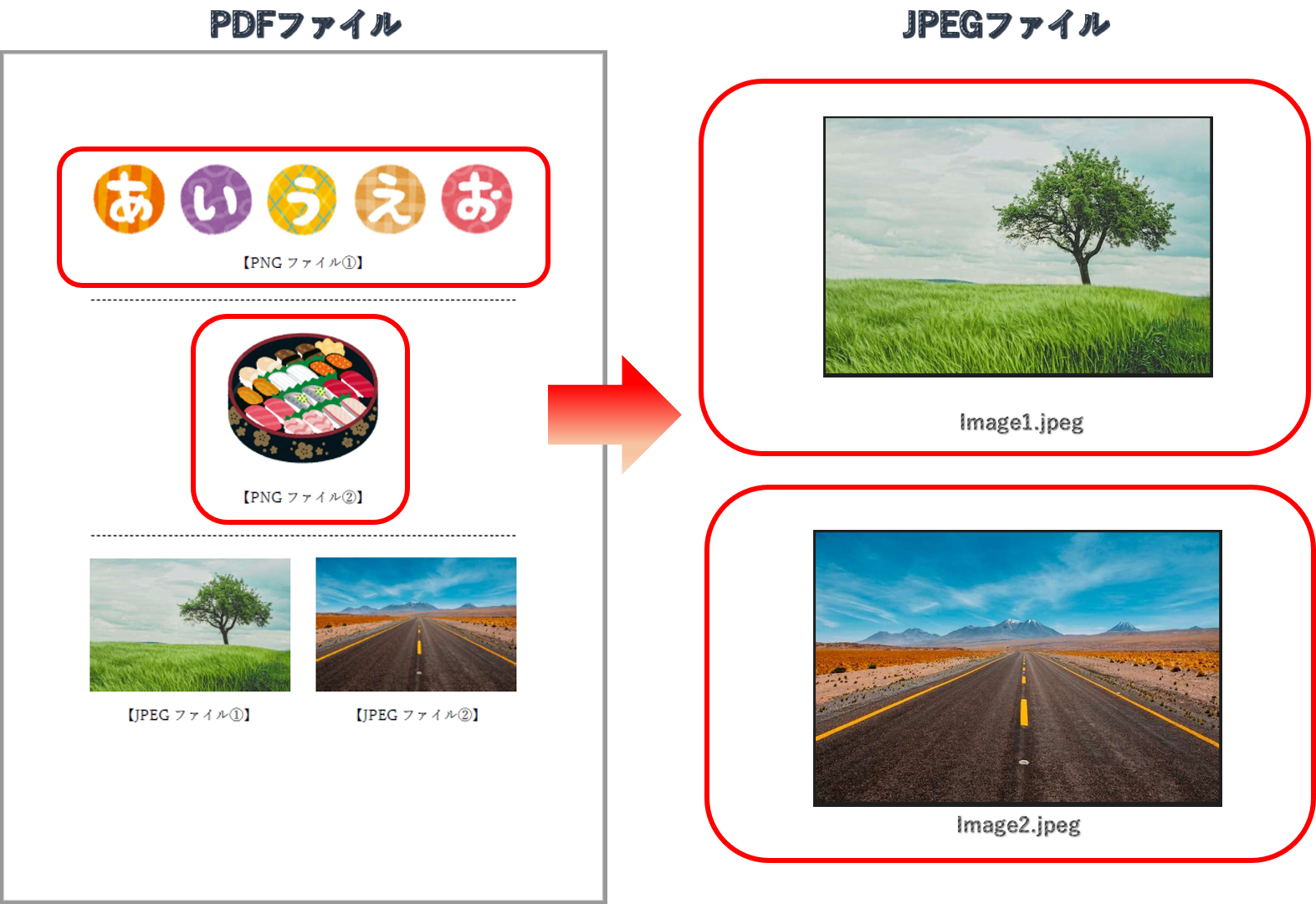
まとめ
この記事では、PyPDF4を使用した、PDFから画像を抽出する方法について、ご説明しました。
本記事を参考に、ぜひ試してみて下さい。
参考
Python学習用おすすめ教材
Pythonの基本を学びたい方向け
統計学基礎を学びたい方向け
Pythonの統計解析を学びたい方向け
おすすめプログラミングスクール
Pythonをはじめ、プログラミングを学ぶなら、TechAcademy(テックアカデミー)がおすすめです。
私も入っていますが、好きな時間に気軽にオンラインで学べますので、何より楽しいです。
現役エンジニアからマンツーマンで学べるので、一人では中々続かない人にも、向いていると思います。
無料体験ができますので、まずは試してみてください!
